
![人工知能と相場とコンピューターと|第13回 21世紀の技術[奥村尚]](https://fx-koryaku.com/wp-content/uploads/2021/05/okumura-202104-1.jpg)


画期的なプロダクトはこの先、生まれるのか
この連載で今まで言及してきた20世紀は、ハードウェアの時代でした。1940年代の真空管コンピュータからスーパーコンピュータに至る進化は、全ての産業が恩恵を受けています。月面着陸を成し遂げたアポロ11号(1969年)、音速旅客で欧米を結んだコンコルド(1975年)、再利用型の有人宇宙船スペースシャトル(1981年)のような宇宙技術、自動車(20世紀全般)、新幹線(1964年、画像①)、ジャンボジェット(1970年)、自動改札地下鉄(1969年)のような運輸技術、テフロン、ナイロン、カーボンファイバ、セラミックスなどの新素材、電子デバイスと歩調を合わせて進化した家電もありますね。
 出典:リニア・鉄道館HP
出典:リニア・鉄道館HP
こうした時代の中で、マンガや映画の世界ではAIとか知性を持ったロボットが登場し、21世紀初頭には私もそうした世界が実現すると思っていたものです。現実はそうでもなく、知性ロボットどころか、まともに走れるロボットすら登場していません。20世紀の乗り物は21世紀でも進歩がありません。新幹線も飛行機も自動車も、ハードウェアという観点では行きつくところまでたどり着き、大きな進化はできないように思えます。
そうした中、21世紀においては求められている技術や開発の主体は、20世紀のようなハードウェアの進化ではなく、人間のように振る舞うAIを活用した処理を実装し、安全に心地良く使うソフトウェアやサービスにフォーカスされてきています。
しかし、既に21世紀になって20年が経過したにもかかわらず、画期的なプロダクトはありません。インターネットの発達によって時間や移動の価値観は変わりましたが、これは行動の変革であり、技術的には30年前からあったものです。「鉄腕アトム」のようなAIロボット、「2001年宇宙の旅」のような考えるコンピュータは遠のいています。スローペースです。人類の脳を模倣するのは、まだまだ難しいということでしょう。
第三次AIブームは2021年も継続中
ここで、21世紀のAIの話に移る前に20世紀におけるAIの歴史を簡単におさらいしておきましょう。
第二次世界大戦で開発された真空管コンピュータは、AIという概念を生みました。それを研究テーマとして第一次AIブームが生まれ、理論や概念が先行します。1950年のAIの知性を判定するチューリングテストや1956年のダートマス会議です。
現在のAIの礎となる理論やプログラミング言語、データとロジックの設計思想など、多くがこの時代に生まれましたが、人間を上回る能力というレベルの高い要求には応えられず、ブームは1960年代で終わります。ただ、大学や政府機関での研究分野として確立され、研究所も創設されたことは、その後の発展に大きく寄与することになります。
1970年代は冬の時代でしたが、パソコンの普及で小規模であればエキスパートシステムが実用になることも示されました。そして1980年代に再びAIブームが訪れます。けん引したのは、日本の第5世代研究プロジェクトです。残念ながら投入したリソースに対して研究成果が期待以下と判断され、再び冬の時代がやってきます。
実は得られた技術は、現在あるものと違いはありません。ニューラルネットワークは、脳の神経細胞ネットワークを模倣していますが、これは現在のディープラーニングの最重要な概念です。ただ、コンピュータの性能が壁となりました。この時代の貢献は、高機能パソコンの普及で、大学の研究室や個人レベルでも研究や開発ができるようになったことでしょう。
結局、そうした研究の結晶がIBMの「Deep Blue(ディープ・ブルー)」の前身となり、AIマシン(ディープ・ブルー)がチェスの世界チャンピオンを破った1997年を境として、第三次AIブームが始まりました。そのブームが2021年の今でも継続しています。AIが人間最強の現役チャンピオンに勝ったわけですから、さすがに期待されたわけです。
総務省の情報通信白書(平成28年版)に、ちょうどよいAI研究の歴史の年表があるので掲載します(画像②)。このように、20世紀でテーマに上がってきたAIに関連する要素技術は21世紀に引き継がれています。ここで、AIと直接の関係はないのですが、ビッグデータという言葉もAIと同時に使われることが多くなってきました。それに関連するP2Pという技術もあり、これは暗号資産(仮想通貨)として金融に深く関わっていますので、この機会に紹介しておきましょう。
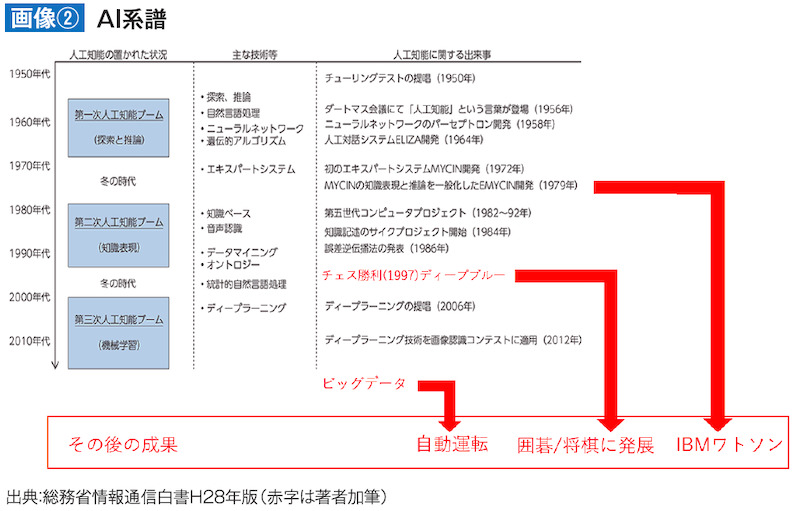
出典:総務省情報通信白書H28年版(赤字は著者加筆)
ビッグデータとP2P
ビッグデータとは、要するに巨大なデータのことですが、インターネット上のデータを意味する場合は「多様さを含む巨大なデータ」という意味があります。
1970年代から、表形式の2次元、時間軸を加えて3次元の巨大データを構造化データベース(DB)に蓄積しデータ解析が行われてきました。瞬間につく株価データ解析や、爆発前後の解析を行う原爆実験、巨大な加速器を使った素粒子実験などは代表的なビッグデータ解析例です。
この時代はサーバにDBを一元管理してデータ処理します。DB上では処理はシーケンシャル(直列)であり、パラレル(並列)ではありません。これは金融のオンラインリアルタイムトランザクション(OLTP)には適しています。例えば、残額1万円の銀行口座で、ほぼ同時にATMと窓口で1万円の出金がある場合、処理が一列に並んで最初の処理で1万円の出金を行い、2番目の処理は残金ゼロで出金不可、という処理が行えます。出金をパラレルに行うと、最初の出金処理が終わらないうちに二つ目の出金処理が進むので、都合が悪いのです。金融機関では、いわゆる第三次オンライン処理と呼びます。管理コストがかかる欠点はあるものの、処理速度では問題ありませんでした。
21世紀に入り、映像や音までデジタル化され、それがWebで一般化してくると、ネット上の音、動画のような非構造化データを用いて解析する手法が出てきました(画像③)。また、プログラムの挙動をテキストデータで細かく吐き出すシステムログ情報を使ってシステム間統合や監視を行う手法も登場しました。
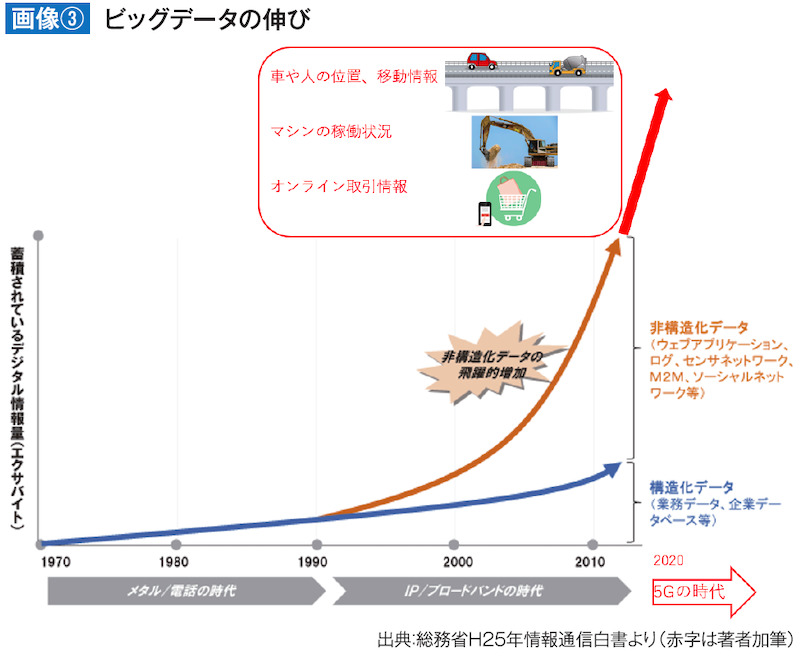
出典:総務省H25年情報通信白書より(赤字は著者加筆)
そうなってくると、DBの処理速度だけでなく、大きなデータの格納にも数段上の能力が要求されてきます。ソリューションとして代表的なものは「Hadoop」です。この技術は、膨大なWeb上のコンテンツをデータから分散し検索を迅速にするための技術です。
1990年代前半、Web検索のDBは人手でメンテナンス作業を行っていたのですが、世界的な規模でWebサイトが広がったため、Webを自動的に「はい回り」情報を集めるクローラーが作られました。しかし、DBを一つのサーバに集中するとあまりにデータが巨大であるため、既成DB製品では処理がかなり重くなってきます。そこでGoogleは、データを分割してコンピュータを複数に分け、並列で高速処理するプロジェクトを進行し、積極的に論文を発表しました。
特に2004年の分散コンピューティング技術論文(MapReduce:大規模クラスタ上でのデータ処理の簡素化)をきっかけに、米国Yahoo!のエンジニアがオープンプラットフォーム開発プロジェクトとしてスタートさせたのが、Hadoopです。現在は世界規模のコミュニティで進んでいます。
個々の分散されたサーバも一つのストレージのように扱え、複数のサーバを束ねて一つの処理もできます。処理時間も分散処理によって並列化されるので、ノード数を増やしてスケール化ができます。サーバが故障しても他のノードがジョブを分担して遂行するのは、落ちない処理系というインターネットの特徴を身にまとったアーキテクチャです。このため、全データについて複数のコピーが(どこかの)ノードに保管されています。
音、画像、動画のような非構造化データでも対応できる柔軟性を持ち、分散ノードが増えるほど処理能力が向上します。分散ノードを増やすのは単に追加するだけで、管理作業も必要ありません。Hadoopは業務に使うことが多く、一つの論理ネットワーク(要するにLAN)で完結するのが原則です。しかし、インターネットが介在しても同じように機能させるように発展できます。これがグリッドコンピューティングです。
SONYのPS3は、2006年に発売されたゲーム機ですが、IBM、東芝と共同開発したCellチップを搭載しており、実際IBMは2008年にCellベースのプロセッサを1万2240個使ったスーパーコンピュータ「Roadrunner(ロードランナー)」を米エネルギー省のロスアラモス国立研究所に納入しました。処理速度1026テラFLOPSは当時の世界一でした。
2007年には、PS3でスタンフォード大学の分散コンピューティングプロジェクト「Folding@home」に誰でも参加できるよう機能拡張がなされ、2012年に終了するまで、延べ1500万人が参加、1000テラFLOPSの能力があることを示しました(画像④)。2010年には米空軍もPS3を使って500テラFLOPSのスーパーコンピュータを開発しています。
P2PはPeer to Peerを略した言葉で、サーバを必要とせずに複数相手の端末と自分の端末が直につながる技術です。仲間が増えたり消滅したりしても問題が発生しません。これはグリッドコンピューティングの一種です。同種の相手と異種の相手を区別したり、メッセージや仲間をやりとりしたり、仲間認証に暗号を使います。この技術を使うと、仲間と非仲間の集合を分けたり、仲間Aさんが持っているはずの残高情報をBさん、Cさんが断片的に持ち、常に正しい残高をチェックし合うことが可能です。これが、暗号資産が要求する技術であり、サーバ運用者がいない中でも通貨ポジションを増減できるわけです。
ところで、サーバがないのに接続状況が流動的で多数の対等な端末がつながるノード群に初めて参加する人はどうするのでしょうか。いくつかの方法がありますが、最初に接続する相手を初期値として持っておくのが最も簡単な方法です。隠しサーバですね。暗号資産では、売買時にポジション情報と次回接続相手を送付する手段も取られます。
なお、スマホでのSNSや、LINEなどチャットアプリは運営会社がサーバを用意していてログイン管理をします。P2Pに見えますが、携帯電話同士はダイレクトにはネットワークされていません。
※この記事は、FX攻略.com2021年4月号(2021年2月20日発売)の記事を転載・再編集したものです。本文で書かれている相場情報は現在の相場とは異なりますのでご注意ください。
\投資ECメディア「GogoJungle」で連載中!/

・「人工知能と相場とコンピューターと」連載記事まとめはこちら



「これからFXを始めよう」と思ったとき、意外と悩んでしまうのがFX会社、取引口座選びではないでしょうか? でも大丈夫。ご安心ください。先輩トレーダー達も最初は初心者。みんなが同じ悩みを通ってきているんです。
10年以上にわたってFX月刊誌を出版してきた老舗FXメディア「FX攻略.com」編集部が、FX用語を知らない人でもわかるようにFX会社、取引口座のポイントを解説しました!
取り上げているFX会社は、金融商品取引業の登録をしている国内FX業者です。口座開設は基本的に無料ですので、まずは気になったところで2〜3つ口座開設してみて、実際に比べてみてはいかがでしょうか。
\FX会社によって違うところをチェック/
| スプレッド | FX取引における取引コスト。狭いほうが望ましい。 |
|---|---|
| 約定力 | 狙った価格で注文が通りやすいかどうか。 |
| スワップポイント | 高水準かどうか。高金利通貨の取り扱いの数。 |
| 取引単位 | 少額取引ができるかどうか。運用資金が少ないなら要チェック。 |
| 取引ツール | 提供されるPC・スマホ取引ツールの使いやすさ。MT4ができるかどうか。オリジナルの分析ツールの有無。 |
| シストレ・自動売買 | 裁量取引とは別に自動売買のサービスがあるかどうか。 |
| サポート体制 | サポート内容や対応可能時間の違いをチェック。 |
| 教育コンテンツ | 配信されるマーケット情報や投資家向けコンテンツの有無。 |
| キャンペーン | 新規口座開設時や口座利用者向け各種キャンペーンの内容。 |




![人工知能と相場とコンピューターと|第15回 それでも地球は回っている[奥村尚]](https://fx-koryaku.com/wp-content/uploads/2021/06/okumura-bnr-20210624-640x360.jpg)
![【犬トレーダーがるちゅーぶFXX】[Masato Shindo]]](https://fx-koryaku.com/wp-content/uploads/2020/07/garutubefxx-00.png)
![トレンドを自動的に追いかける優れもの!トレール注文を使いこなそう[遠藤寿保]](https://fx-koryaku.com/wp-content/uploads/2020/11/endo-fx-201704-1.jpg)






